

🕒 背景:倒计时48小时的“渡劫”
最近这两天,课题组的气氛那是相当焦灼。一边是一个大项目的结题,另一边是新项目的开题,两个Deadline撞车,必须在48小时内全部搞定。
老板一声令下,全员进入“战时状态”,通宵熬夜是跑不掉了。但最搞心态的不是写本子,而是那些极其繁琐、重复、毫无技术含量但又必须精准的“体力活”:
改PPT格式:几百页的PPT,里面无数个表格,必须全部改成学术标准的“三线表”。
地质绘图:在CDR里对着综合测井柱状图,把所有黄色的砂体部分填充岩性花纹(黑点)。以前这活儿是师弟师妹用鼠标一个一个点上去的,点完手都废了。
转图:把PDF里的图表转成高清图片放到汇报文档里。
看着大家盯着屏幕机械地点击鼠标,我这个程序员DNA动了。拒绝当Human Robot(人类机器人)! 我花了一点时间写了三个Python脚本,把这些活儿全包圆了。
🛠️ 任务一:一键统一PPT“三线表” (拒绝XML报错版)
痛点:PPT自带的表格样式太花哨,学术汇报要求顶底线粗、栏目线细、无竖线的“三线表”。几十页PPT改下来,人会疯的。
技术难点: Python的 python-pptx 库虽然强大,但在处理**表格边框(Borders)**时非常反人类。它没有直接的API来设置“上边框粗细”,必须深入到底层 XML 元素进行操作。而且,如果操作不当(比如标签顺序不对),生成的PPT会直接报错打不开。
解决方案: 采用**“先破后立”**的暴力美学。
遍历所有单元格。
对于每一条边,先删除其现有的XML定义(避免冲突)。
重建符合标准的XML元素(线宽、颜色、样式)。
特别注意:第一行顶线加粗,第一行底线变细,最后一行底线加粗,其余全清空。

核心代码片段:
from pptx.oxml.ns import qn
from pptx.oxml.xmlchemy import OxmlElement
# 核心:设置单元格边框的底层函数
def set_cell_border(cell, side, border_color="000000", border_width='12700', visible=True):
tc = cell._tc
tcPr = tc.get_or_add_tcPr()
tag_map = {'left': 'a:lnL', 'right': 'a:lnR', 'top': 'a:lnT', 'bottom': 'a:lnB'}
tag_name = tag_map.get(side)
# 关键步骤:先查找并删除旧定义,防止XML结构损坏导致PPT无法打开
# 注意:查找时必须用 qn() 包装
existing_ln = tcPr.find(qn(tag_name))
if existing_ln is not None:
tcPr.remove(existing_ln)
# 创建新定义(注意:创建元素时直接用字符串,不要用qn)
ln = OxmlElement(tag_name)
if visible:
ln.set('w', str(border_width)) # 12700 EMU ≈ 1pt
# ... (设置颜色、实线等属性,略) ...
tcPr.append(ln)
else:
# 显式写入无填充,确保没有边框
noFill = OxmlElement('a:noFill')
ln.append(noFill)
tcPr.append(ln)
# 逻辑:根据行号决定画哪条线
def apply_three_line_style(table):
THICK_WIDTH = 28575 # ~2.25 pt
THIN_WIDTH = 9525 # ~0.75 pt
for row_idx, row in enumerate(table.rows):
for cell in row.cells:
# 清除左右竖线
set_cell_border(cell, 'left', visible=False)
set_cell_border(cell, 'right', visible=False)
# ... (根据 row_idx 判断 top/bottom 画粗线还是细线) ...
避坑指南:在
python-pptx中操作XML,find元素时必须用qn('a:lnL'),但OxmlElement创建元素时只能用'a:lnL',否则会报KeyError: '{http...'错误。
🎨 任务二:智能地质绘图——给砂体“戴帽子”
痛点:在测井解释中,黄色通常代表砂岩。我们需要在PDF图件的黄色区域填充黑点(岩性花纹)。但有两个难点:
不能遮挡文字:图上的深度数据、孔隙度数值不能被黑点盖住。
区域限制:这次的任务只需要处理下部1/3的层位(比如这就代表了目标层段)。
技术方案:PyMuPDF (渲染PDF) + OpenCV (计算机视觉) 这其实是一个典型的CV问题。
颜色分割:将PDF渲染为图片,转为HSV色彩空间,提取黄色区域掩膜(Mask)。

OCR/文本保护:利用
PyMuPDF提取所有文字的 Bounding Box(边界框),在掩膜上把这些矩形区域“挖掉”。区域裁剪:计算图像高度,只对
y > 2/3 * height的区域进行扫描。矢量回填:根据生成的最终掩膜,计算出坐标,再调用
PyMuPDF的绘图接口,在原始PDF上画矢量圆点(这样放大依然清晰,不是贴图)。
效果展示: (此处假装有图:左边是原图,中间是提取的黄色Mask减去文字框,右边是最终打点的PDF)
核心代码片段:
import cv2
import fitz
import numpy as np
# ... (省略打开PDF和颜色阈值设置) ...
# 步骤A:生成文字避让掩膜
mask_text_bboxes = np.zeros((h_img, w_img), np.uint8)
text_words = page.get_text("words") # 获取单词级精度的坐标
for word in text_words:
# 将PDF坐标转换为像素坐标,并适当外扩(padding)
# ...
# 在掩膜上画白色矩形,表示“禁区”
cv2.rectangle(mask_text_bboxes, (x0, y0), (x1, y1), 255, -1)
# 步骤B:逻辑运算生成最终绘制区
# 最终区域 = (是黄色) AND (不是文字区)
mask_final = cv2.bitwise_and(mask_yellow, cv2.bitwise_not(mask_text_bboxes))
# 步骤C:只处理下1/3
start_y_scan = int(h_img * (2 / 3))
# 步骤D:遍历像素,矢量绘图
for y in range(start_y_scan, h_img, step_px):
for x in range(0, w_img, step_px):
if mask_final[y, x] > 0:
# 像素坐标 -> PDF点坐标
pdf_x = x / zoom
pdf_y = y / zoom
shape.draw_circle((pdf_x, pdf_y), dot_radius)
shape.commit(overlay=True) # 提交绘图
这套代码跑下来,原本需要人眼识别、鼠标点击几千次的工作,现在5秒钟搞定一页,而且绝对不会点错或者盖住文字。
🖼️ 任务三:PDF转高清大图
痛点:写汇报材料时,直接截图PDF太糊,用专业软件转又太慢。
解决方案: PyMuPDF 的 get_pixmap 配合 Matrix 矩阵变换,可以轻松实现任意DPI的输出。
# 300 DPI = 打印级清晰度
zoom = 300 / 72.0
mat = fitz.Matrix(zoom, zoom)
pix = page.get_pixmap(matrix=mat, alpha=False)
pix.save("output.png")
这个虽然简单,但是配合批量处理脚本,几百个图件瞬间转好,直接拖进Word里,那清晰度,看着就舒服。
📚 任务四:参考文献“大清洗”——拒绝手动一一搜索
痛点: 参考文献:“格式全是乱的!去把这几十篇文献全部统一成 GB/T 7714 标准格式!” 我看了一眼手里的 input.txt,简直是灾难现场:
有的只有作者名(
Arps J J);有的年份在前,有的年份在后;
有的是完整的非标准引用,有的是半截残句;
中英文混杂。
如果手动一条条复制到谷歌学术去搜,再点“引用”复制,几百条下来,我的 Ctrl+C 和 Ctrl+V 键帽都要盘包浆了。而且,如果你用Python爬虫去批量爬谷歌学术,分分钟会被封IP。
技术方案: 既然不能暴力爬虫,那就用**“半自动化辅助”**策略。
智能清洗:用正则表达式(Regex)做一个“洗衣机”,把原始文本里的
[J]、页码、年份、et al等干扰项洗掉,只保留最核心的标题。HTML 仪表盘:Python 生成一个本地
.html网页。双保险策略:针对每一条文献,生成两个按钮:
🔍 提取版搜索:搜清洗后的纯标题(命中率高)。
📄 原文搜索:如果清洗失败(切错了),直接搜原文(谷歌算法很强,也能搜到)。
人机协作:我只负责点按钮 -> 点引用 -> 复制。完全规避了反爬虫机制,效率提升10倍。
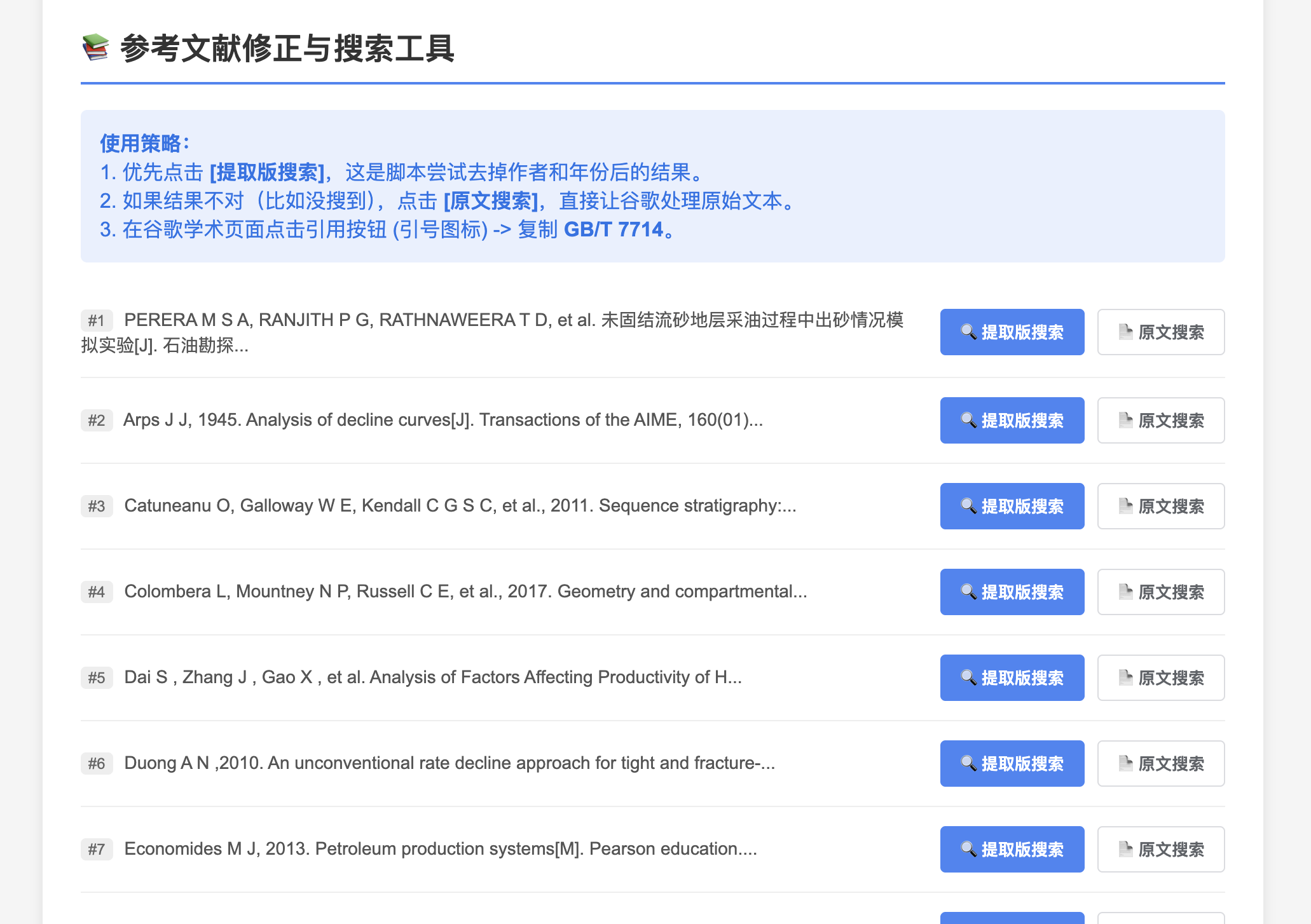
效果展示: 运行脚本后生成一个网页,左手点链接跳转谷歌学术,右手直接复制 GB/T 7714。以前一上午的活,现在喝杯咖啡的功夫就搞定了。
核心代码片段:
Python
import re
import os
import urllib.parse
# 核心逻辑:智能清洗文本,提取潜在标题
def clean_text_smart(text):
original = text
text = text.strip()
# 1. 掐头去尾:去掉 [J] 标识和页码
text = re.sub(r'\[[a-zA-Z]+\][.]?.*$', '', text)
text = re.sub(r'[,.]?\s*\d+[:]\s*\d+[-]\d+.*$', '', text)
# 2. 锚点定位:利用年份 (19xx/20xx) 或 "et al" 来分割
# 如果年份出现在前半段,取年份之后的内容作为标题
year_match = re.search(r'([,.(]\s*(?:19|20)\d{2}[).]?)\s*', text)
if year_match:
if year_match.start() < len(text) * 0.6:
potential_title = text[year_match.end():].strip()
if len(potential_title) > 5:
text = potential_title
# 3. 兜底:如果洗得太干净变成了空字符串,就返回原文本
if len(text) < 3:
return original
return text
# ... (文件读取代码略) ...
# 核心逻辑:生成 HTML 仪表盘
html_content = """
<div class="container">
<h2>📚 参考文献修正与搜索工具</h2>
"""
for line in lines:
clean_title = clean_text_smart(line)
# 生成两个链接:一个搜清洗版,一个搜原版
url_clean = f"https://scholar.google.com/scholar?q={urllib.parse.quote(clean_title)}"
url_raw = f"https://scholar.google.com/scholar?q={urllib.parse.quote(line)}"
html_content += f"""
<div class="row">
<div class="text-area">{line[:80]}...</div>
<div class="btn-group">
<a href="{url_clean}" target="_blank" class="btn btn-primary">🔍 提取版搜索</a>
<a href="{url_raw}" target="_blank" class="btn btn-secondary">📄 原文搜索</a>
</div>
</div>
"""
# 保存并提示用户打开
with open(output_html_path, 'w', encoding='utf-8') as f:
f.write(html_content + "</div></body></html>")
print(f"👉 请双击打开文件: {output_html_path}")
这个脚本最骚的地方在于它不联网,只生成链接。把繁琐的文本处理交给Python,把搜索判定交给谷歌,把最后的确认权交给自己。完美闭环!
💡 结语
在科研这条路上,我们经常会被各种琐事缠身。有时候,停下来花半小时写个脚本,可能比硬着头皮干两天效率要高得多。