

一个特别有意思、也特别容易被讲糊涂的话题:
同样是一条 GR 测井曲线,为什么经过不同的 INPEFA 算法处理以后,会长出三条性格完全不同的曲线?
第一,这三个曲线到底分别是怎么来的?
第二,Burg 算法、AR 模型、预测误差、积分,这几步在数学上到底在干什么?
第三,为什么 legacy_global_INPEFA 会出现大斜坡,而 raw_INPEFA 和 grouped_raw_INPEFA 看起来更像局部波动?
第四,AR_ORDER=8 到底是什么意思?有 9000 个数据点,难道就是 9000 阶函数吗?
第五,WINDOW_LENGTH=480 和 120 又到底代表什么?它真的是 480 米和 120 米吗?
沿着这条思考链,把代码、数学、信号处理直觉和地质解释,全部串成一条清清楚楚的逻辑线。
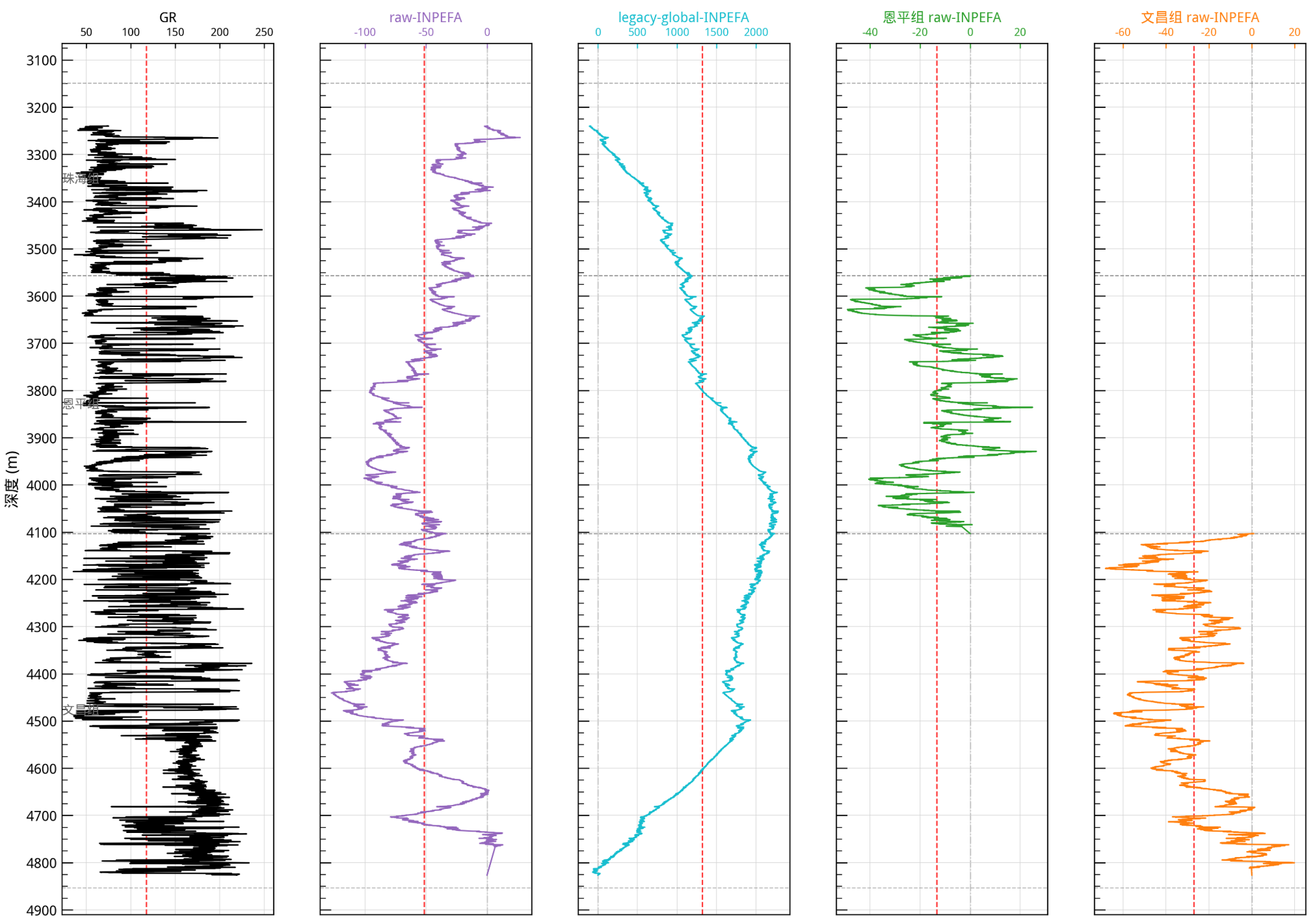
一、先把这三条曲线摆清楚:它们不是同一个东西的三个配色版本
最终输出了三条核心曲线:
legacy_global_INPEFAraw_INPEFAgrouped_raw_INPEFA_Enping_Wenchang
它们虽然都和 AR 预测误差、积分有关,但本质上回答的是三个不同的问题。
1. legacy_global_INPEFA 问的是:
“当前点偏离整段井的总体平均规律有多大?”
2. raw_INPEFA 问的是:
“当前点偏离它附近这一段局部背景有多大?”
3. grouped_raw_INPEFA 问的是:
“当前点偏离它所在地层组内部的局部背景有多大?”
而且它还多做了一件事:
强行切断跨组记忆。
所以,这三条曲线真正的区别,不只是窗口大小不同,而是:
参考背景不同
模型是否动态更新不同
是否允许跨组记忆不同
最后拼接方式不同
二、代码底层共同的数学骨架:它们都在做“预测误差积分”
先把最基础的框架讲清楚。
设一条测井曲线写成离散序列:

这里每个 (x_t) 对应某个深度点的 GR 值。
无论是全局版还是局部版,它们都在做一件事:
先用前面的若干数据去预测当前值,再看当前值和预测值差多少,最后把这种“差”累计起来。
这个“差”就是预测误差:
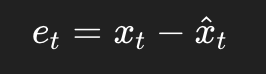
其中:
xt是真实值
hat{xt} 是模型预测值
et 是预测误差,也就是 PEFA 的核心来源
INPEFA 则是对这串误差做累计和:
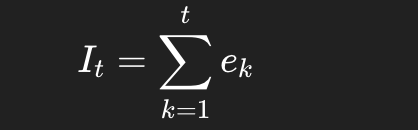
如果是反向版本,本质上就是从另一端累加。
你可以把它理解成:
PEFA 是“每一步出没出偏差”
INPEFA 是“这些偏差一路累计下来,形成了怎样的总趋势”
三、Burg + AR 模型到底在干什么?
这是最深的地方,也是最核心的地方。
1. AR 模型是什么?
AR 是自回归模型。
它的思想非常朴素:
当前值,可以由前面若干个值线性组合出来。
本质上就是一种机器学习,来实现
一个 (p) 阶 AR 模型写成:
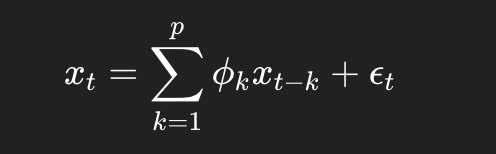
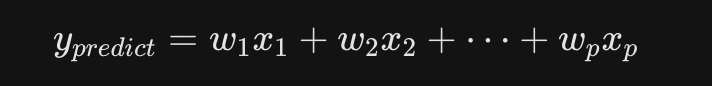
Burg 算法的精妙之处在于它定义了一个更严苛的对称损失函数:

因为 AR 模型是纯线性的,它的 Loss 面是一个完美的碗状(凸函数)。Burg 算法不需要像梯度下降那样盲人摸象般地慢慢走,它借用了一种名为 Levinson-Durbin 递归的数学技巧,作为它的解析解求解器(Solver)。它能一步到位,极其高效地直接算出最优权重。
Burg 算法在求解过程中,每一步都会计算一个反射系数 。由于它的数学构造(分子是互相关,分母是自相关),天然自带了一个强制约束。 这在机器学习视角的等价意义就是:强制进行权重衰减,保证无论训练数据多么异常(比如遇到了极端的岩性突变),模型学出来的权重都不会爆炸,系统永远是收敛和稳定的。
Train(训练阶段):用 Burg 算法把整口井(或者滑窗内)的数据当作训练集,训练出一个能够代表“地层正常背景规律”的 Baseline 模型。
Inference(推理阶段):用训练好的模型对测井曲线进行逐点预测(这就是你代码里用 FIR 滤波器做卷积的那一步)。
Residual Analysis(残差分析):将实际的测井值减去模型的预测值,得到残差(Prediction Error)。在机器学习中,残差异常大,就说明遇到了模型无法认知的“新事物”(即重大的沉积环境突变)。
Post-processing(后处理):对这些残差进行积分累加,把高频噪声抹平,让隐藏的低频地质信号显露出来。
所以本质上用的是 AR(8)。
2. Burg 算法做了什么?
_burg_ar() 是做了一种 Burg 型递推估计。
它的目标是求出一组稳定的预测误差滤波器系数。
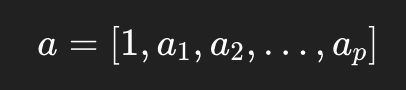
预测代码是:
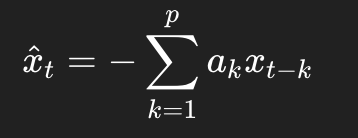
3. 为什么要先去均值?
无论全局还是局部预测,在建模前都会在某个层面上做均值处理。
比如全局版本中:
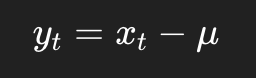
其中:
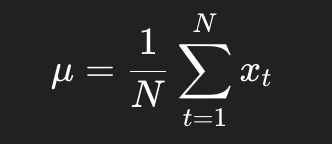
直觉上很简单:
如果整口井 GR 都在 80 左右波动,那模型真正该学的不是“80”这个大常数,而是“围绕 80 是怎么上下摆动的”。
所以,去均值不是因为“平稳过程必须零均值”,而是因为:
把常数背景去掉以后,AR 模型更容易专注于波动关系本身。
四、第一条曲线:legacy_global_INPEFA 的完整推导
现在正式进入第一条曲线。
1. 它的代码入口
核心函数是:
_legacy_global_one_direction(data, ar_order)
2. 第一步:整段去均值
代码里做的是:
其中:
这一步相当于先把整段井的整体背景拉平。
3. 第二步:整段只建一次模型
然后它对整个序列 (y_t) 一次性估计一套固定的 Burg 系数:
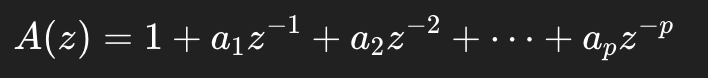
这里 (p=8)。
注意,这里不是每走一步重新建模,而是:
整段数据只建模一次。
所以它相当于默认整段井里存在一个统一的平均规律。
4. 第三步:固定滤波器扫完整段曲线
代码用了:
valid_error = np.convolve(centered_data, pef_filter, mode='valid')
这一步数学上就是:
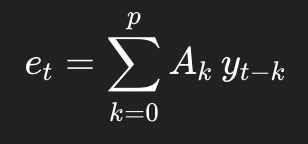
这就是一个固定的预测误差滤波器在全局扫整段数据。
直觉上,你可以把它想成一个“统一标准的质检尺子”:
如果某段岩性变化符合整口井的平均规律,误差就小
如果某段明显不符合全局背景,误差就大
5. 第四步:误差累加成 INPEFA
最后:
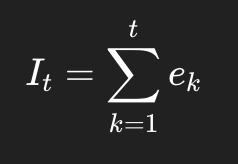
代码里就是:
np.cumsum(prediction_error)
也就是说,在原始顺序下,当前点的参考背景更偏向它下方的数据,而不是上方的数据。
6. 这条曲线为什么容易长成“大斜坡”?
因为它的“异常参照物”是整段井的统一背景。
假设***组是一大段持续高 GR 泥岩。
如果全井平均 GR 比它低很多,那么在这一大段里,误差可能长期保持同号。
比如:
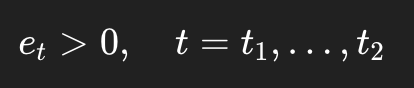
那么积分以后:
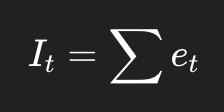
就会持续往一个方向走,形成一条大斜坡。
所以 legacy_global_INPEFA 的典型特点是:
更容易保留慢变趋势
更容易体现整段背景偏差
更容易画出大尺度斜坡
但要注意,这不等于它自动识别了“三级旋回”。
更准确地说,它更容易保留全局低频背景,而这些低频背景是否对应三级旋回,还要靠地质解释。
五、第二条曲线:raw_INPEFA 的完整推导
现在看第二条。
1. 它的代码入口
核心函数是:
calculate_pefa_raw(data, window_length, ar_order, direction=...)
内部核心是:
_local_pefa_one_direction(data, window_length, ar_order)
2. 它和全局版最大的不同:每走一步都重新建模
对于每个位置 (i),它取一个局部窗口:
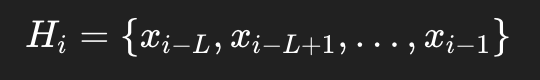
其中:

然后在这段历史 (Hi) 上现算一套 Burg 系数,再预测 (xi)。
所以预测公式变成:
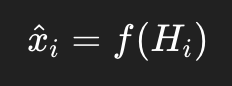
而不是像全局版那样,用整段只生成一套固定参数。
3. 这里有一个必须讲清的坑:WINDOW_LENGTH=480 不是天然的 480 米
在代码里,window_length 首先表示的是:
480 个样点
只有当采样间隔恰好是 1 m 时,才近似等于 480 m。
如果采样间隔是 0.125 m,那么:
480 个样点}= 60 m
所以你在解释“三级、四级旋回”的时候,不能偷懒把窗口长度直接当米数,除非确认采样间隔。
4. 第一步:对每个点建立局部训练集
对于第 (i) 个点,历史窗口为:
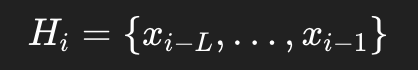
再在这段窗口内部做去均值:
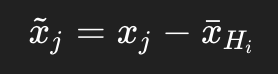
其中:
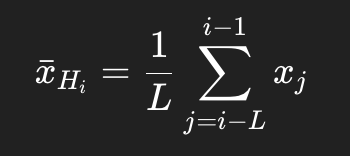
然后估计局部 Burg 系数。
5. 第二步:局部 AR(8) 预测当前点
虽然窗口是 (L=480),但单次预测真正直接使用的滞后项仍然只有:
p=8
也就是说:
WINDOW_LENGTH_RAW决定的是建模时看多长历史AR_ORDER=8决定的是预测时直接用几个滞后项
这是两个不同概念。
于是预测值写成:
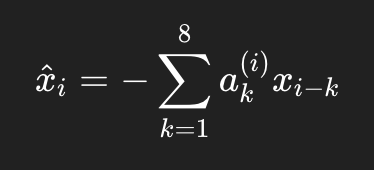
这里上标 ((i)) 表示:
第 (i) 个点的系数,是在第 (i) 个局部窗口里重新估出来的。
于是误差为:
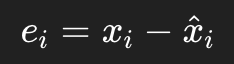
6. 第三步:整条局部误差算完以后,再统一标准化
这是非常关键的代码事实。
不是每个窗口都各自归一化,而是整条 pefa 算完以后再做:
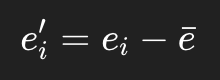
如果开启标准化,再做:
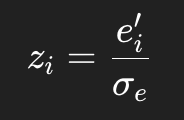
其中:
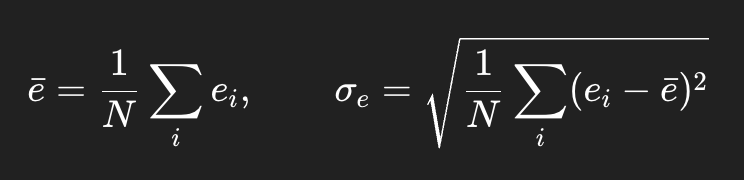
最后再积分:
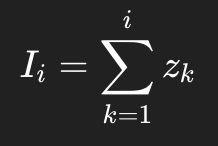
或者 reverse 情况下做反向累计。
7. 这条曲线为什么比全局版更“局部”?
因为它的背景不是“整口井平均规律”,而是“当前位置附近这一个窗口的局部规律”。
比如,刚进入一段厚泥岩时,窗口里可能还保留大量上覆砂岩信息,于是模型会觉得高 GR 很异常,误差会很大。
但如果窗口继续向下滑,滑窗内部越来越多都是高 GR 泥岩,那么模型就会逐渐把这种高 GR 当成新常态。
所以它具有一种工程上很直观的“遗忘机制”:
太久远的背景,会随着窗口滑动逐渐失效。
8. 它是不是“带通滤波器”?
可以借这个词帮助理解,但不能说得太死。
更准确地说:
它会比全局模型更弱化超低频背景
最后积分又会平滑掉一部分很高频的噪声
所以经验上更容易突出中尺度变化
但它不是教科书里那种固定传递函数的严格 LTI 带通滤波器,因为它的系数 (a_k^{(i)}) 是随位置变化的。
所以最稳妥的表述是:
raw_INPEFA 是一种时变、自适应、局部背景参照下的预测误差积分曲线。
六、第三条曲线:grouped_raw_INPEFA 的完整推导
这条曲线是最“工程化”、也最“好用”的一条。
1. 它先按组切断数据
代码先选出:
***组
***组
然后对每个组分别取掩码:
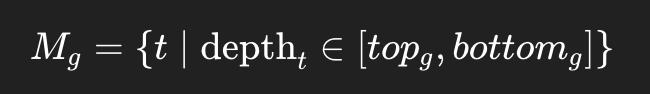
于是整条井变成若干个彼此隔离的数据块:

2. 每个组内部再单独跑一次 raw 流程
对于某个组 (g),它内部再做:
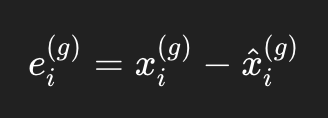
其中预测模型是:
只在本组内部训练
使用窗口长度
WINDOW_LENGTH_GROUPED仍然是
AR_ORDER=8
于是对每个组,都得到一条独立的局部误差序列,再做组内归一化:
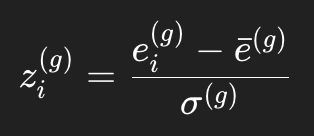
再积分:
3. 这条曲线为什么对组内细节特别敏感?
因为它同时做了两件狠事:
第一,不允许跨组记忆。
第二,窗口更短。
于是某个组内部那些原本埋在大背景里的小波动,更容易被放大。
比如某一组整体变化很平稳,局部方差很小:
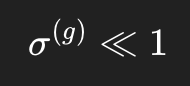
此时即便出现一个看起来不太大的局部异常,归一化后也会相对放大:
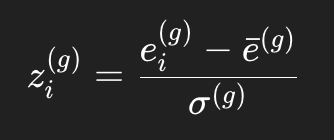
这就是为什么它特别适合看组内更细尺度的变化。
4. 最后一步:数学拼接
每个组独立算完以后,直接画出来会断开。
所以代码做了一个纯数学平移。
如果是 reverse,代码逻辑是:
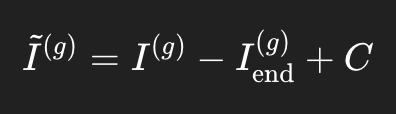
这里 (C) 是上一段的连接值。
如果是 forward,则是把起点对齐。
这一步的本质不是重新生成地质趋势,而只是:
把几段独立曲线在纵坐标上平移一下,让它们视觉上接起来。
5. 这条拼接曲线有什么解释边界?
这是必须强调的。
拼接以后,你可以解释:
某个组内部的波峰波谷
某个组内部哪里更敏感、哪里更平稳
某个组内部的局部节律变化
但你不能很草率地拿不同组之间的绝对高低直接做地质结论。
因为不同组之间的连接,带有人工平移的成分。
所以这条曲线的正确使用方式是:
看段内形态,不强行解释跨段绝对标高。
七、几个最关键的认知纠正
1. AR_ORDER=8 不是说“八次函数”,也不是“9000 阶函数”
AR(8) 的意思只是:
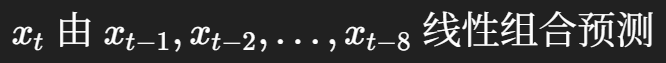
它本质上是一个8 维线性模型,不是中学意义上的 (x^8) 那种八次多项式图像。
2. WINDOW_LENGTH 不是 AR 阶数
这是最容易混淆的地方。
AR_ORDER=8:直接滞后项数WINDOW_LENGTH=480/120:训练局部模型时使用的历史样本长度
所以窗口再大,也不意味着模型阶数变高。
3. reverse 不只是“反向积分”
代码里,reverse 等于:
先把数据倒过来
再建模
再预测
再积分
最后翻回原顺序
所以 reverse 同时改了:
建模方向
累加方向
4. 第三条曲线“去均值以后两头都回零”是不对的
更准确地说:
如果误差满足
那么:
forward 积分时,末端会回到 0
reverse 积分时,首端会回到 0
不是两头都自动归零。
5. legacy_global 不是“无限阶模型”
它是:
全局一次建模
但模型阶数仍然是 8
所以“全局”说的是建模范围,不是阶数无限。
八、把整个过程用“机器学习语言”再翻译一次
这个视角非常适合口播,因为听起来直观。
但要先讲一句准确的话:
Burg/AR 更属于经典时间序列和信号处理方法,不是现在工程语境里常说的那种机器学习模型。
不过,我们可以借机器学习语言去理解它。
第一幕:模型架构——它像线性回归,但它首先是一个时间序列预测器
先别急着上“旋回”“边界”“沉积演化”这些大词。
从算法角度看,这一切的起点,其实非常朴素:
用过去若干个样点,去预测当前样点。
这就是自回归模型,AR(ppp)。
它的标准思想可以写成:
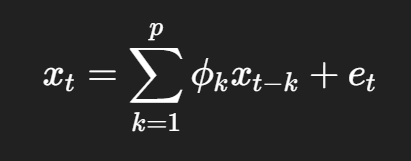
从机器学习视角看,这确实很像一个“滞后特征做输入的线性模型”:
特征:过去 p 个样点
标签:当前样点
参数:p个权重
所以如果只讲直觉,你完全可以把它理解成一种“时间序列版的线性回归”。
但这里一定要补一句严谨的话:
它不是普通 i.i.d. 假设下的多元线性回归。
因为这里的输入特征不是互相独立的列,而是同一条序列的滞后项,它们天然高度相关。
代码 _burg_ar() 返回的不是直接写成教材里 ϕk\phi_kϕk 形式的参数,而是这一套 AR/PEF 多项式系数:
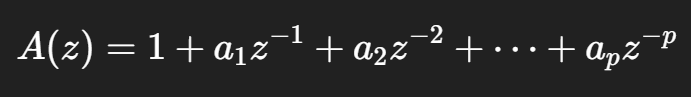
于是,在代码语境里,预测值写成:
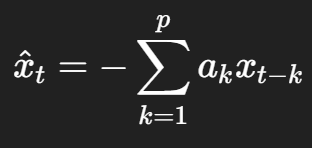
用过去 p 个样点的线性组合,去预测当前样点。
所以,第一幕的结论可以概括成一句话:
Burg 算法的底座模型,本质上是一个基于滞后特征的线性预测器;只是代码里采用的是 PEF/AR 多项式系数写法,所以预测公式前面带负号。
第二幕:损失函数——Burg 的精髓,不是只看一个方向,而是双向约束
模型有了,下一步就是:
怎样衡量“这组参数好不好”?
普通线性预测最自然的想法,是只看一个方向的误差:
用过去预测现在,看误差平方和是不是最小。
但 Burg 的精髓不在“单向看得准”,而在:
它同时约束前向预测误差和后向预测误差。
也就是说,在第 m 阶递推时,它关注的是两套误差:
forward error:顺着序列往前预测的误差
backward error:反过来往后回推的误差
更严谨地写,可以记成:
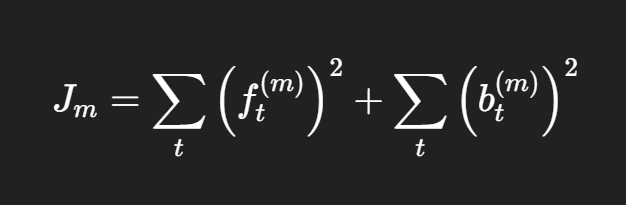
这里有个很重要的纠正:
我们不能把它讲成“普通 MSE 一定容易过拟合,所以 Burg 更高级”。
这个说法太满。
更准确的说法应该是:
在有限长度时间序列、边界效应明显、又希望参数稳定的场景里,只看单向误差的估计方法,往往不如 Burg 这种双向约束的递推方法稳健。
换句话说,Burg 的优势不在于“别人都错,它绝对对”,而在于:
它更充分地榨取了有限序列中的信息
它在短数据和谱估计问题里通常更稳
它从结构上控制了不稳定解的出现
所以第二幕的核心不是“Loss 越花哨越高级”,而是:
Burg 用前向 + 后向两套误差一起约束参数,让模型学到的不是单边凑出来的规律,而是两边都尽量自洽的规律。
第三幕:优化器与训练过程——它不是梯度下降,没有学习率,但它确实在“逐阶生长”
到了这里,很多有机器学习背景的人会自然追问:
“那它怎么训练?学习率多少?迭代几轮?有没有 epoch?”
答案很有意思:
没有学习率,也没有那种神经网络式的 epoch。
因为代码实现的不是梯度下降,也不是 Adam,更不是“把一个 Loss 丢给黑盒优化器慢慢调”。
代码做的是 Burg recursion。
核心结构就在这里:
for _ in range(order):
...
mu = ...
...
a[1:-1] = current_a[1:] + mu * current_a[1:][::-1]它的意思不是“扫同一批数据 100 轮”,而是:
每一轮把模型阶数加 1,然后基于当前前向/后向误差,更新一套更高阶的预测器。
所以,如果你设定:
p=8p = 8p=8
那么训练过程不是“8 个 epoch”,而是:
第 1 阶:先找到一个最优的一阶预测器
第 2 阶:在一阶基础上继续加一个参数
第 3 阶:继续往上生长
…
第 8 阶:最终长成一个 8 阶预测器
这是一种逐阶递推构造模型复杂度的过程。