

碎碎念
不说了先上图
所以说,代替老师去开会去了,但是嘛,有个问题,长达接近两个小时的时间,现在的语音转文字问题都完成不了了,主要是因为时长问题,要么需要收费,要么是慢的要死,转换到一半因为各种网络问题中断了,因此只能尝试自己实现这个功能了,老规矩,先用SDFMU的圣遗物,搭建环境就好。
实操
sudo apt update
sudo apt install ffmpeg
pip install setuptools-rust
pip install openai-whisper pydub代码
import whisper
from pydub import AudioSegment
import os
import glob
import torch
from multiprocessing import Pool, cpu_count
import time
import multiprocessing
# --- 可配置参数 ---
# Whisper 模型选择: 'tiny', 'base', 'small', 'medium', 'large'
# 'base' 在速度和准确性之间取得了很好的平衡。
# 'large' 精度最高,但需要更多显存和时间。
MODEL_NAME = "large"
# 音频文件格式
AUDIO_FORMAT = "m4a"
def convert_m4a_to_wav(m4a_filepath: str) -> str:
"""
将 M4A 音频文件转换为 WAV 格式。
Args:
m4a_filepath (str): 输入的 M4A 文件路径。
Returns:
str: 输出的 WAV 文件路径, 如果失败则为空字符串。
"""
wav_filepath = os.path.splitext(m4a_filepath)[0] + ".wav"
try:
audio = AudioSegment.from_file(m4a_filepath, format="m4a")
audio.export(wav_filepath, format="wav")
return wav_filepath
except Exception as e:
print(f"[错误] 文件 {m4a_filepath} 转换失败: {e}")
return ""
def transcribe_task(args):
"""
单个音频文件的完整处理工作流(转换和转录),由一个独立的进程执行。
Args:
args (tuple): 包含 (m4a_filepath, gpu_id) 的元组。
"""
m4a_filepath, gpu_id = args
process_name = f"[GPU-{gpu_id} | {os.path.basename(m4a_filepath)}]"
# 1. 设置当前进程使用的GPU
# os.environ['CUDA_VISIBLE_DEVICES'] 会限制这个进程只能看到指定的GPU
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id)
print(f"{process_name} 开始处理...")
# 2. 转换 M4A 到 WAV
print(f"{process_name} 正在将 M4A 转换为 WAV...")
wav_file = convert_m4a_to_wav(m4a_filepath)
if not wav_file:
print(f"{process_name} 转换失败,任务终止。")
return
# 3. 加载 Whisper 模型到指定的GPU
# 由于已经设置了 CUDA_VISIBLE_DEVICES,PyTorch 会自动将模型加载到正确的 GPU 上
print(f"{process_name} 正在加载 Whisper '{MODEL_NAME}' 模型...")
try:
model = whisper.load_model(MODEL_NAME)
except Exception as e:
print(f"{process_name} 加载模型失败: {e}")
return
# 4. 执行转录
print(f"{process_name} 开始转录 WAV 文件...")
try:
# 增加更多参数以获得更好的中文识别效果
result = model.transcribe(
wav_file,
language="zh", # 指定语言为中文
fp16=torch.cuda.is_available(), # 自动检测是否使用 fp16
verbose=False # 在并行处理时建议关闭详细日志,避免输出混乱
)
transcribed_text = result["text"]
except Exception as e:
print(f"{process_name} 转录时发生错误: {e}")
return
# 5. 打印并保存结果
print(f"{process_name} 转录完成!")
print("-" * 20)
print(f"文件: {os.path.basename(m4a_filepath)}\n识别结果: {transcribed_text[:100]}...")
print("-" * 20)
output_txt_file = os.path.splitext(m4a_filepath)[0] + ".txt"
try:
with open(output_txt_file, 'w', encoding='utf-8') as f:
f.write(transcribed_text)
print(f"{process_name} 结果已保存到: {output_txt_file}")
except Exception as e:
print(f"{process_name} 保存文件时出错: {e}")
# 6. (可选) 清理临时的WAV文件
try:
os.remove(wav_file)
print(f"{process_name} 已删除临时文件: {wav_file}")
except OSError as e:
print(f"{process_name} 删除临时文件 {wav_file} 失败: {e}")
# --- 主程序 ---
if __name__ == "__main__":
# 设置多进程启动方法为 'spawn',必须在程序入口处设置
# 这是解决 "Cannot re-initialize CUDA in forked subprocess" 错误的关键
multiprocessing.set_start_method('spawn', force=True)
start_time = time.time()
# 检查是否有可用的NVIDIA GPU
if not torch.cuda.is_available():
print("错误:未检测到可用的 NVIDIA GPU。请检查您的驱动和 PyTorch 安装。")
exit()
num_gpus = torch.cuda.device_count()
print(f"检测到 {num_gpus} 张可用的 GPU。")
# 查找当前目录下所有的 m4a 文件
audio_files = glob.glob(f'*.{AUDIO_FORMAT}')
if not audio_files:
print(f"错误:在当前目录下未找到任何 '.{AUDIO_FORMAT}' 文件。")
exit()
print(f"找到 {len(audio_files)} 个音频文件准备处理。")
# 为每个文件创建一个任务,并轮流分配 GPU
# 格式为 [(文件路径1, GPU_ID_1), (文件路径2, GPU_ID_2), ...]
tasks = [(file_path, i % num_gpus) for i, file_path in enumerate(audio_files)]
# 使用与GPU数量相等的进程池来并行处理任务
# Pool 会自动管理进程的创建和销毁
with Pool(processes=num_gpus) as pool:
pool.map(transcribe_task, tasks)
end_time = time.time()
print("\n--- 所有任务处理完毕 ---")
print(f"总计用时: {end_time - start_time:.2f} 秒")
单卡环境优化
import whisper
from pydub import AudioSegment
import os
import torch
from multiprocessing import Pool, set_start_method
import time
# --- 可配置参数 ---
MODEL_NAME = "large"
# 支持的音频格式列表 (你可以根据需要添加)
SUPPORTED_EXTENSIONS = ('.mp3', '.m4a', '.wav', '.flac', '.aac', '.ogg', '.wma', '.amr')
def convert_to_standard_wav(source_filepath: str) -> str:
"""
智能转换函数:
1. 自动识别输入格式(不强制指定 format)。
2. 将音频统一转换为 Whisper 最喜欢的格式 (16000Hz, 单声道)。
"""
wav_filepath = os.path.splitext(source_filepath)[0] + ".wav"
# 如果源文件本身就是符合要求的 wav,且没损坏,理论上可以跳过,
# 但为了稳健,这里统一重新处理一遍,清洗数据。
try:
# Pydub 会调用 ffmpeg 自动探测文件格式,不需要人工指定 format="xxx"
audio = AudioSegment.from_file(source_filepath)
# --- 优化步骤:预处理音频 ---
# Whisper 内部会将音频重采样为 16000Hz 并转为单声道。
# 我们在这里提前做,可以避免 Whisper 内部的隐式转换,并标准化输入。
audio = audio.set_frame_rate(16000).set_channels(1)
audio.export(wav_filepath, format="wav")
return wav_filepath
except Exception as e:
print(f"[错误] 文件 {source_filepath} 预处理失败: {e}")
return ""
def transcribe_task(args):
"""
单个音频处理进程
"""
file_path, gpu_id = args
filename = os.path.basename(file_path)
process_name = f"[GPU-{gpu_id} | {filename}]"
# 1. 绑定 GPU
os.environ['CUDA_VISIBLE_DEVICES'] = str(gpu_id)
print(f"{process_name} 开始处理...")
# 2. 转换/标准化音频
# 这一步现在非常重要,因为它负责“清洗”各种乱七八糟的格式
print(f"{process_name} 正在标准化音频格式 (16kHZ Mono WAV)...")
wav_file = convert_to_standard_wav(file_path)
if not wav_file:
print(f"{process_name} 音频预处理失败,跳过。")
return
# 3. 加载模型
print(f"{process_name} 正在加载 Whisper '{MODEL_NAME}' 模型...")
try:
model = whisper.load_model(MODEL_NAME)
except Exception as e:
print(f"{process_name} 模型加载失败: {e}")
return
# 4. 转录
print(f"{process_name} 开始识别内容...")
try:
result = model.transcribe(
wav_file,
language="zh",
fp16=torch.cuda.is_available(),
verbose=False
)
transcribed_text = result["text"]
except Exception as e:
print(f"{process_name} 识别过程出错: {e}")
# 即使出错也尝试清理临时文件
if os.path.exists(wav_file) and wav_file != file_path:
os.remove(wav_file)
return
# 5. 保存结果
output_txt_file = os.path.splitext(file_path)[0] + ".txt"
try:
with open(output_txt_file, 'w', encoding='utf-8') as f:
f.write(transcribed_text)
preview = transcribed_text[:50].replace('\n', ' ')
print(f"{process_name} 完成! 结果: {preview}...")
print(f"{process_name} 已保存: {output_txt_file}")
except Exception as e:
print(f"{process_name} 保存结果失败: {e}")
# 6. 清理临时 WAV 文件 (避免占用磁盘)
# 注意:如果原文件就是 wav,我们要小心不要删掉原文件(虽然上面的逻辑生成的是同名文件覆盖,但为了保险起见)
# 在这里,因为 convert_to_standard_wav 生成的文件名和原文件名如果是wav会冲突吗?
# os.path.splitext('a.wav')[0] + '.wav' == 'a.wav'。
# 为了避免覆盖原文件或误删,建议我们在转换时加个后缀,或者判断一下。
# **修正逻辑**:为了安全,我们在 convert 函数生成的 wav 文件名通常还是加个 .temp 比较好,或者确保输入不是wav。
# 但为了代码简单,这里只判断:如果生成的 wav 路径 不等于 原文件路径,才删除。
if wav_file != file_path:
try:
os.remove(wav_file)
# print(f"{process_name} 临时文件已清理。")
except:
pass
# --- 主程序 ---
if __name__ == "__main__":
start_time = time.time()
if not torch.cuda.is_available():
print("错误:未检测到 GPU。")
exit()
# 1. 在循环开始前,只加载一次模型!(解决 IO 瓶颈)
print("正在加载 Whisper 模型 (只加载一次)...")
model = whisper.load_model(MODEL_NAME)
print("模型加载完毕。")
# 2. 扫描文件
all_files = os.listdir('.')
audio_files = [f for f in all_files if f.lower().endswith(SUPPORTED_EXTENSIONS)]
if not audio_files:
print("未找到音频文件。")
exit()
print(f"找到 {len(audio_files)} 个文件。")
# 3. 简单的串行循环 (4090 跑这个非常快,无需多进程)
for i, file_path in enumerate(audio_files):
print(f"[{i+1}/{len(audio_files)}] 正在处理: {file_path}")
# 预处理
wav_file = convert_to_standard_wav(file_path)
if not wav_file: continue
# 转录
try:
result = model.transcribe(wav_file, language="zh", verbose=False)
# 保存
txt_path = os.path.splitext(file_path)[0] + ".txt"
with open(txt_path, 'w', encoding='utf-8') as f:
f.write(result["text"])
print(f" -> 已保存: {txt_path}")
except Exception as e:
print(f" -> 错误: {e}")
# 清理
if wav_file != file_path and os.path.exists(wav_file):
os.remove(wav_file)
end_time = time.time()
print(f"\n总耗时: {end_time - start_time:.2f} 秒")然后把转换结果交给GeMini总结一下,穿插着PPT内容即可
会议纪要
会议主题: “挑战杯”竞赛经验分享、政策解读与2027年备赛战略研讨
主要内容:
1. 分享往届“挑战杯”参赛经验与心得。
2. 深入解读“挑战杯”的赛制、评审逻辑及价值。
3. 为备战后续赛事,特别是2027年在本校举办有本场优势,进行早期动员和战略布局。
一、 会议核心内容与关键结论
1. 战略高度重视: “挑战杯”是与“互联网+”大赛同等重要的A1级学科竞赛,对教师职称评定、学生毕业与综合能力提升、学院科研成果转化均有重大意义。
2. 2027主场优势: 学校已成功申办2027年“挑战杯”,拥有巨大的主场优势,全校及学院应从现在开始系统性布局,力争实现突破。
3. 从“科研项目”到“竞赛作品”的思维转变: 会议反复强调,竞赛项目不能是科研报告的简单平移。必须学会“讲一个完整的故事”,从解决社会痛点、满足国家重大需求的角度切入,突出项目的社会价值与应用前景,而不仅仅是展示技术先进性。
(例如:技术是怎样帮助贫困山区的牧民,或者如何保护被侵蚀佛像等等)
4. “学生主体”是评审核心: 评委极其关注学生在项目中的真实参与度和贡献度。成果(专利、论文)必须有学生署名(至少是第二作者),PPT和答辩中要充分体现学生的身影(如野外采样、实验操作的照片等),避免项目看起来像“老师的成果,学生来汇报”。
5. 长期规划与团队构建是成功的关键: “挑战杯”战线长(约10个月),需要组建稳定、分工明确、积极配合的团队。建议从大一、研一的优秀学生中选拔“好苗子”,进行为期2年的长期培养和成果积累。
二、 主要发言人观点摘要
1. 张珊同学(研究生,省赛省一获奖者)经验分享

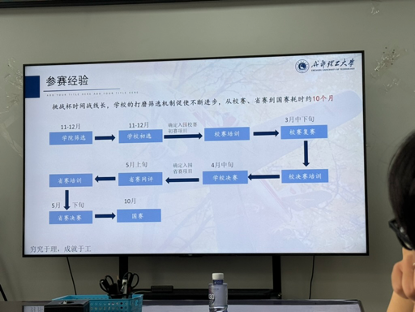
• 参赛流程:
o 前期准备: 读懂赛事规则 -> 与导师确定选题(需具创新与落地价值) -> 撰写申报书与制作PPT。
o 时间线: 整个过程耗时约10个月,从校内选拔(11-12月)到省赛(次年5月)再到国赛(10月),期间学校会组织多轮培训和打磨。
• 关键心得与教训:
o 申报书: 切忌通篇文字、内容空洞。初版因“啰嗦潦草”落选。修改后逻辑清晰,通过图表、数据突出项目亮点、痛点及解决方案,结构完整性是核心。

o PPT制作:
原则: 少文字、多图表,排版简洁、干净、专业。
内容: 标题明确突出重点,逻辑清晰,不应为追求美观而忽略实质内容。

o 现场答辩:
准备: 提前撰写逐字稿,梳理逻辑,反复演练直至脱稿。
核心: 在5分钟内,给评委“讲一个完整的故事”,逻辑线条必须清晰。
团队与支持: 感谢导师的细心指导、团队成员的明确分工与积极配合,以及学校团委提供的专家指导、后勤保障等全方位支持。

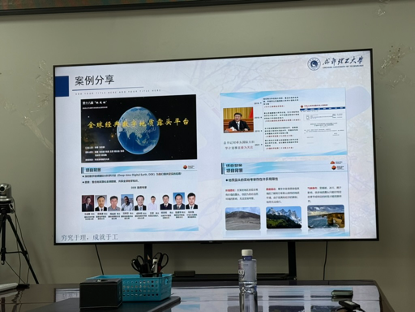
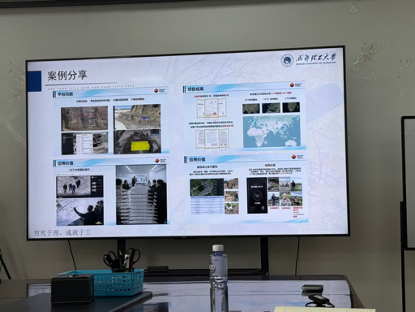
• 项目展示逻辑:
o 背景: 结合国家重大需求和行业背景。
o 问题: 阐述项目要解决的痛点和难点。
o 目标与创新: 明确项目目标,与同类产品进行调研对比,突出自身的技术壁垒、创新点和优势。
o 成果与价值: 展示平台功能、成果支撑(专利、论文、媒体报道)及其应用推广价值。
2. 曾老师(竞赛组织负责人)
• “挑战杯”历史与分类:
o 大挑(奇数年): 侧重学术科技发明,分为自然科学论文(仅限本科生)和科技发明制作(研究生为主)两大类。
o 小挑(偶数年): 侧重商业价值和创业计划,分为创业计划和公益创意赛道。
• 成果要求与趋势:
o 科技发明类: 极其看重专利,尤其是“专利群”(十几二十项),这背后是团队和导师的长期积累。
o “师生共创”模式: 借鉴川大、电子科大经验,鼓励老师和学生共同创业,将科研成果转化为公司实体,这在比赛中非常有优势。
o 政策红利: 获得国赛金奖等高级别奖项的项目,在成都落地可获得市、区两级共计百万级的创业补贴。
• 备赛建议:
o 提前布局: 针对2027年主场优势,现在就应开始物色项目和团队。
o 校赛晋级:有校赛选拔、学院推荐、自荐(只要认为自己行就可以上)
o 人员选拔: 建议从大一、研一学生开始培养,确保在参赛时(大三/研三)已有成果积累且仍在校。
3. 唐老师(竞赛组织负责人)
• 竞赛的双重价值:
o 对教师: 国赛一等奖等同于A1级成果,省赛一等奖算是B1成果
o 对学生: 全程参与项目能极大提升综合能力,部分学院可作为毕业要求之一。
• 评委关注的核心:
o 学生真实参与: 评委会反复质疑“这项目是不是学生做的?”。必须通过专利署名(学生名下)、现场照片等材料证明学生深度参与。
o 社会价值: 项目必须与社会重大议题(如减灾防灾、能源安全等)相结合,体现高校的社会责任感。
• 理工科学院的普遍难点:
o 从“技术思维”到“故事思维”的转变: 不能上来就讲技术多牛,要先讲背景、痛点、社会意义,用一个动人的故事来包装技术核心。
• 学院优势与支持:
o 学校团委和学院将提供全方位的支持,包括申报书和PPT的打磨、答辩培训等。
三、后续行动计划
• 行动一:梳理现有成果。 各团队/课题组应系统梳理现有技术成果、专利、论文,评估其转化为竞赛项目的潜力。鼓励跨团队合作,将不同技术融合进一个项目中(如将无人机、三维建模技术用于地质灾害防治)。
• 行动二:提前布局知识产权。 在未来的科研工作中,有意识地将学生(特别是计划参赛的低年级本科或者研一学生)纳入专利发明人或论文作者中,为参赛积累“弹药”。
• 行动三:启动选题与团队组建。 学院将动员导师们开始物色有潜力的项目选题,并选拔大一的优秀学生尽早进入课题组,参与项目。
• 行动四:加强学习与借鉴。 建议各团队多研究学习“挑战杯”官网上的往届国赛获奖作品,分析其选题立意、申报书写法和项目包装逻辑。
• 行动五:寻求支持与合作。 学院将与学校团委紧密合作,为参赛团队提供持续的指导和资源对接。