

学习路线
先开始看鱼书吧,看网上好多人都说是吴恩达+鱼书,现在吴恩达机器学习部分看完了,其中也囊括了神经网络部分,所以说现在可以开始鱼书部分了今天一天的时间把前四章的内容看完了python入门(没看),感知机,神经网络,神经网络学习。这些部分都是吴恩达视频讲过的东西,适当温习就好了
第一章Python入门(省略)
第二章感知机
基本上就是实现,或与非,异或python实现
下面是实现代码
import numpy as np
def AND(x1,x2):
x=np.array([x1,x2])
w=np.array([0.5,0.5])
b=-0.7
tmp=np.sum(w*x)+b
if tmp <= 0:
return 0
else:
return 1
def NAND(x1,x2):
x=np.array([x1,x2])
w=np.array([-0.5,-0.5])
b=0.7
tmp=np.sum(w*x)+b
if tmp <= 0:
return 0
else:
return 1
def OR(x1,x2):
x=np.array([x1,x2])
w=np.array([0.5,0.5])
b=-0.2
tmp=np.sum(w*x)+b
if tmp <= 0:
return 0
else:
return 1
def XOR(x1,x2):
s1=NAND(x1,x2)
s2=OR(x1,x2)
y=AND(s1,s2)
return y
def main():
print("AND(0,0) = ",AND(0,0))
print("AND(1,0) = ",AND(1,0))
print("AND(0,1) = ",AND(0,1))
print("AND(1,1) = ",AND(1,1))
print("NAND(0,0) = ",NAND(0,0))
print("NAND(1,0) = ",NAND(1,0))
print("NAND(0,1) = ",NAND(0,1))
print("NAND(1,1) = ",NAND(1,1))
print("OR(0,0) = ",OR(0,0))
print("OR(1,0) = ",OR(1,0))
print("OR(0,1) = ",OR(0,1))
print("OR(1,1) = ",OR(1,1))
print("XOR(0,0) = ",XOR(0,0))
print("XOR(1,0) = ",XOR(1,0))
print("XOR(0,1) = ",XOR(0,1))
print("XOR(1,1) = ",XOR(1,1))
main()第三章神经网络
分为三层:输入层,中间层,输出层
下图 w,b分别称之为权重和偏置
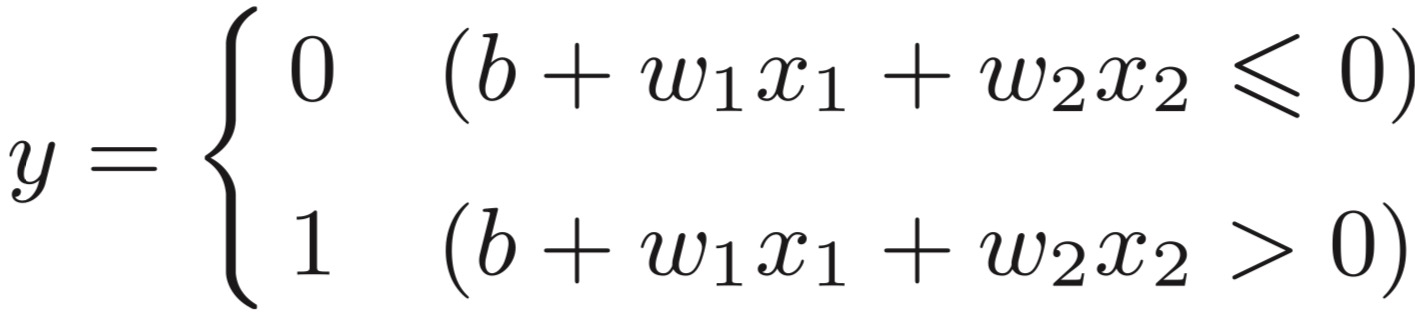
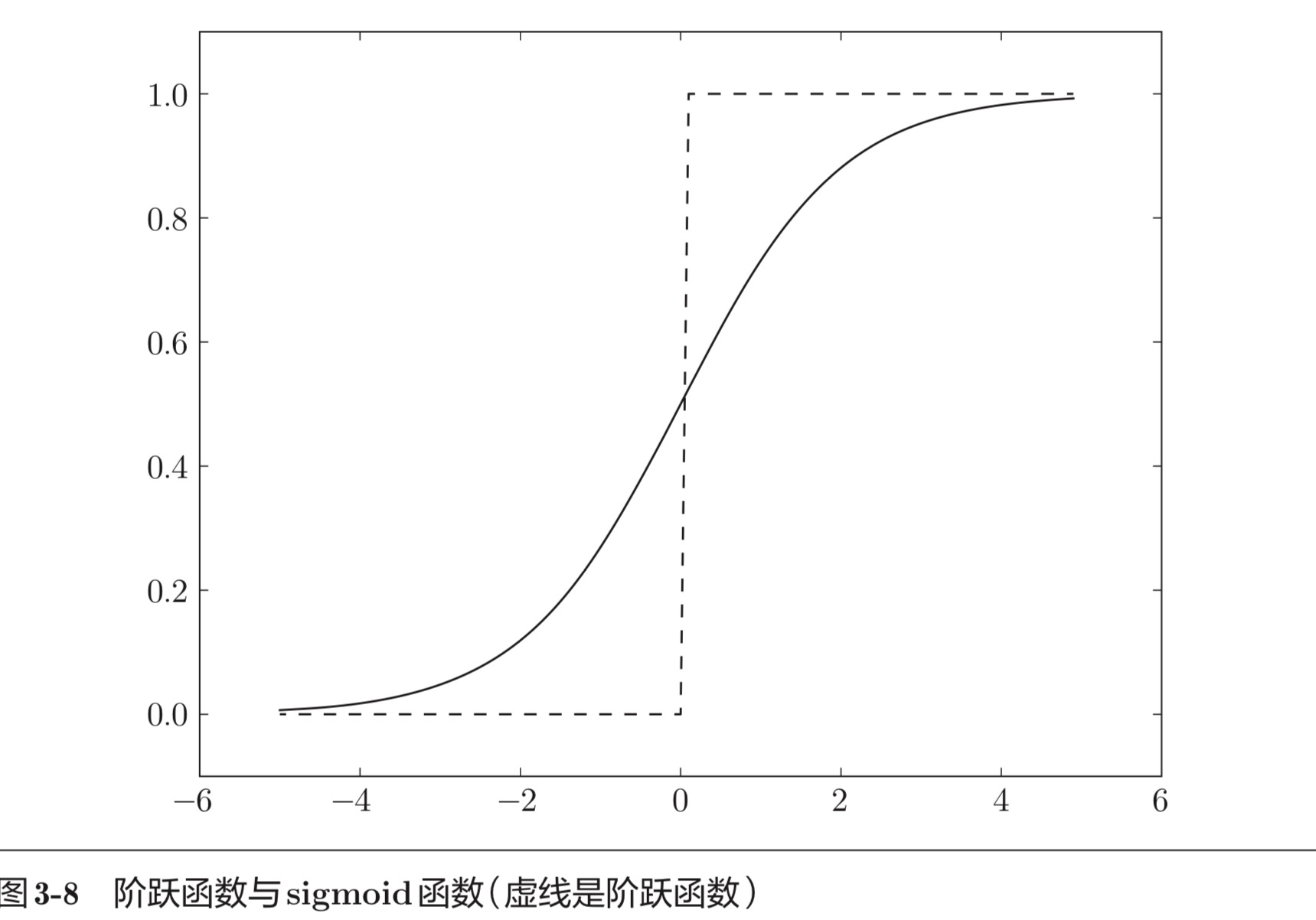
激活函数图像:
常见有sigmoid,relu,阶跃函数,softmax函数,恒等函数
公式表示
阶跃函数:
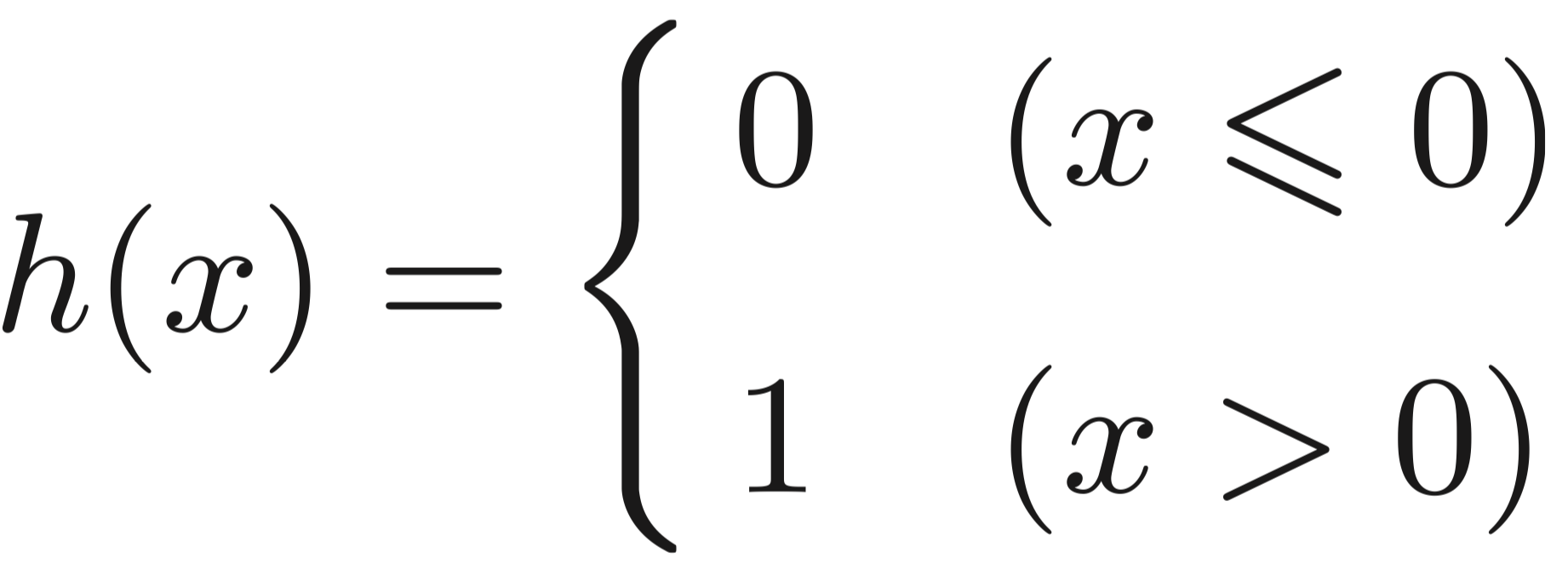
sigmoid函数表示
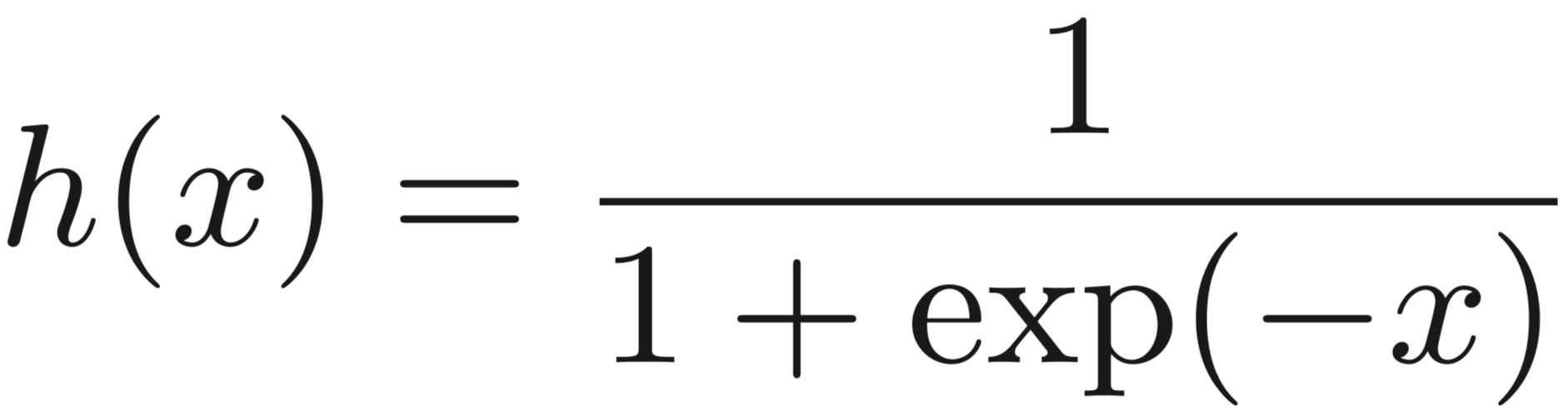
Relu函数表示
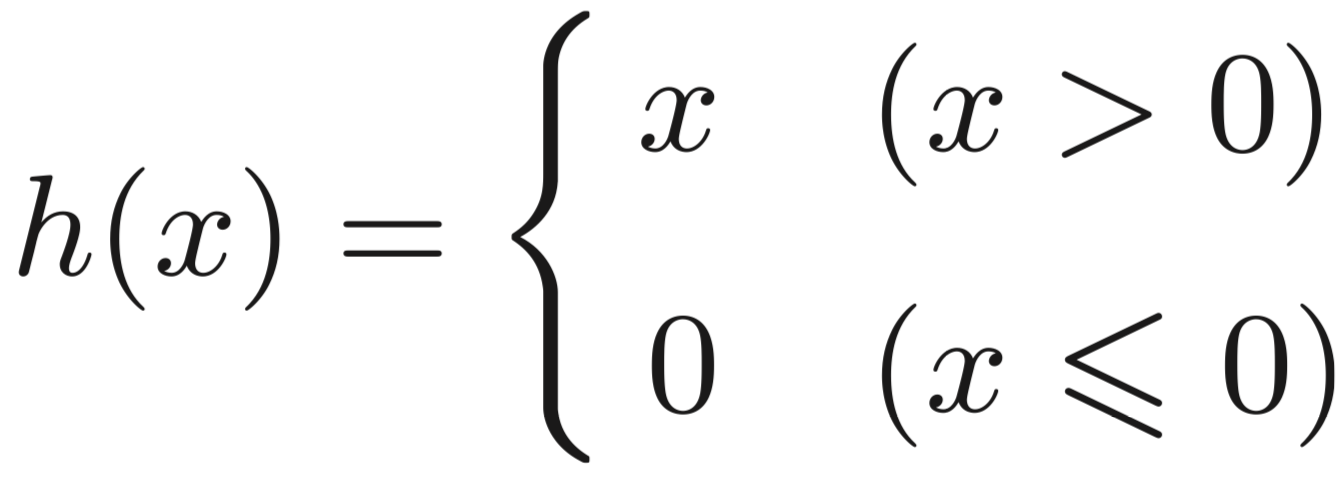
softmax函数
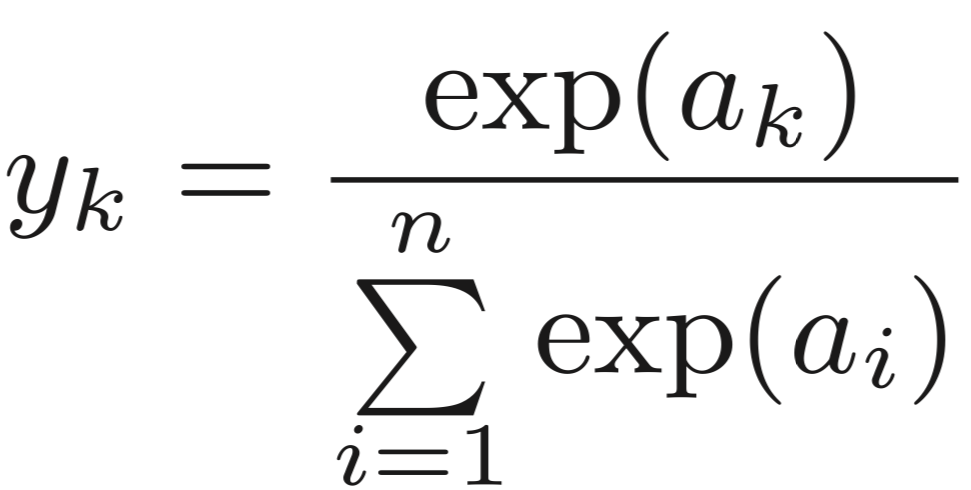
softmax改进版本
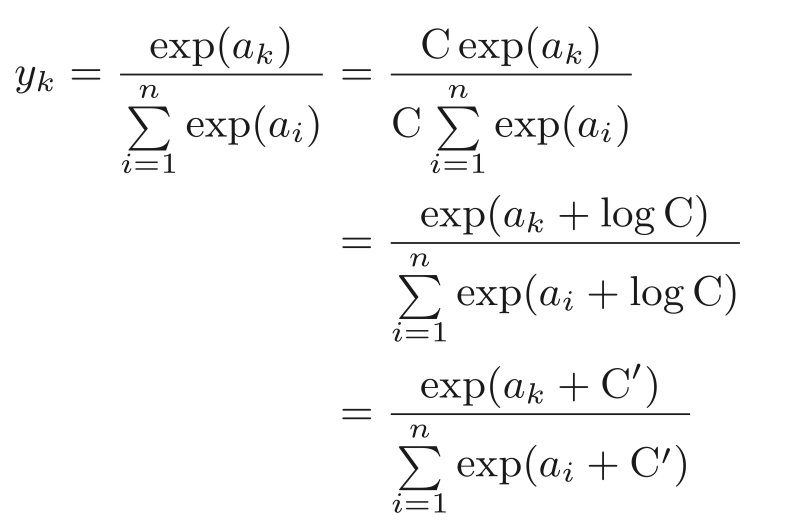
一般来说中间层常用Relu函数,输出层常用sigmoid函数,或者softmax函数,恒等函数
函数Python实现
def relu(x):
"""
ReLU function
:param x: input value
:return: ReLU value
"""
return np.maximum(0, x)
def sigmoid(x):
"""
Sigmoid function
:param x: input value
:return: sigmoid value
"""
return 1 / (1 + np.exp(-x))
def step_function(x):
"""
Step function
:param x: input value
:return: 0 or 1
"""
return np.array(x > 0, dtype=int)
def softmax(x):
"""
Softmax function
:param x: input value
:return: softmax value
"""
exp_x = np.exp(x - np.max(x))
return exp_x / np.sum(exp_x)第四章神经网络学习
1. 从数据中学习
关键概念:
特征量工程 vs 端到端学习(神经网络自动提取特征)
训练集/测试集划分原则(一般80/20或70/30)
泛化能力的重要性
2. 损失函数(Loss Function)
# 均方误差(Mean Squared Error)
def mean_squared_error(y, t):
return 0.5 * np.sum((y - t)**2)
# 交叉熵误差(Cross Entropy Error)
def cross_entropy_error(y, t):
delta = 1e-7 # 防止log(0)溢出
return -np.sum(t * np.log(y + delta))
# 批量版本交叉熵误差(Mini-Batch版本)
def cross_entropy_error_batch(y, t):
if y.ndim == 1:
t = t.reshape(1, t.size)
y = y.reshape(1, y.size)
batch_size = y.shape[0]
return -np.sum(t * np.log(y + 1e-7)) / batch_size3. 梯度下降算法
# 数值梯度计算(中心差分法)
def numerical_gradient(f, x):
h = 1e-4
grad = np.zeros_like(x)
with np.nditer(x, flags=['multi_index'], op_flags=['readwrite']) as it:
while not it.finished:
idx = it.multi_index
tmp_val = x[idx]
# f(x+h)
x[idx] = tmp_val + h
fxh1 = f()
# f(x-h)
x[idx] = tmp_val - h
fxh2 = f()
grad[idx] = (fxh1 - fxh2) / (2*h)
x[idx] = tmp_val # 还原值
it.iternext()
return grad
# 梯度下降优化器
class SGD:
def __init__(self, lr=0.01):
self.lr = lr
def update(self, params, grads):
for key in params.keys():
params[key] -= self.lr * grads[key]4. 误差反向传播算法(关键推导)
计算图构建技巧:
加法节点梯度分配(均等分配)
乘法节点梯度反转(需要交换输入值)
ReLU层梯度传播:∂x∂L={0∂y∂L(x≤0)(x>0)
Affine层(全连接层)梯度计算:
∂W∂L=XT⋅∂Y∂L
∂X∂L=∂Y∂L⋅WT
5. 两层神经网络完整实现
class TwoLayerNet:
def __init__(self, input_size, hidden_size, output_size):
# 参数初始化(Xavier初始化)
self.params = {}
self.params['W1'] = np.sqrt(2.0/input_size) * np.random.randn(input_size, hidden_size)
self.params['b1'] = np.zeros(hidden_size)
self.params['W2'] = np.sqrt(2.0/hidden_size) * np.random.randn(hidden_size, output_size)
self.params['b2'] = np.zeros(output_size)
def predict(self, x):
# 前向传播
W1, b1 = self.params['W1'], self.params['b1']
W2, b2 = self.params['W2'], self.params['b2']
a1 = np.dot(x, W1) + b1
z1 = relu(a1)
a2 = np.dot(z1, W2) + b2
y = softmax(a2)
return y
def loss(self, x, t):
# 计算损失(带L2正则化)
y = self.predict(x)
weight_decay = 0.001 # 正则化系数
W1, W2 = self.params['W1'], self.params['W2']
return cross_entropy_error(y, t) + \
weight_decay * 0.5 * (np.sum(W1**2) + np.sum(W2**2))
def gradient(self, x, t):
# 反向传播计算梯度
grads = {}
batch_num = x.shape[0]
# 前向传播保留中间结果
a1 = np.dot(x, self.params['W1']) + self.params['b1']
z1 = relu(a1)
a2 = np.dot(z1, self.params['W2']) + self.params['b2']
y = softmax(a2)
# 反向传播
dy = (y - t) / batch_num # 交叉熵误差的梯度
grads['W2'] = np.dot(z1.T, dy) + 0.001 * self.params['W2'] # 含正则化项
grads['b2'] = np.sum(dy, axis=0)
da1 = np.dot(dy, self.params['W2'].T)
dz1 = da1 * (a1 > 0).astype(float) # ReLU导数
grads['W1'] = np.dot(x.T, dz1) + 0.001 * self.params['W1']
grads['b1'] = np.sum(dz1, axis=0)
return grads6. 训练流程关键步骤
# 超参数设置
iters_num = 10000 # 迭代次数
batch_size = 100 # 批大小
learning_rate = 0.1
# 数据加载(以MNIST为例)
from dataset.mnist import load_mnist
(x_train, t_train), (x_test, t_test) = load_mnist(normalize=True, one_hot_label=True)
# 网络初始化
network = TwoLayerNet(input_size=784, hidden_size=50, output_size=10)
optimizer = SGD(lr=learning_rate)
# 训练循环
for i in range(iters_num):
# 随机选择mini-batch
batch_mask = np.random.choice(x_train.shape[0], batch_size)
x_batch = x_train[batch_mask]
t_batch = t_train[batch_mask]
# 计算梯度
grad = network.gradient(x_batch, t_batch)
# 参数更新
optimizer.update(network.params, grad)
# 每100次迭代计算准确率
if i % 100 == 0:
train_acc = np.mean(np.argmax(network.predict(x_batch), axis=1) == np.argmax(t_batch, axis=1))
test_acc = np.mean(np.argmax(network.predict(x_test), axis=1) == np.argmax(t_test, axis=1))
print(f"Iter {i}: Train Acc {train_acc:.4f}, Test Acc {test_acc:.4f}")