

碎碎念
目前网上有很多ai换脸的网站,但是无疑有几个问题,首先大多都是收费的,并且还不便宜。然后内容受到监管,某些特定人物不能转换或者用户想干点监管之外的事情,也不行,所以,在我有计算资源的情况下,为什么不能自己部署一个换脸项目呢,绝对自由。说干就干。
问问AI有哪些开源项目可以ai换脸
所以说,通常我们的要求就是,我们没有那么多的源人脸,通常只有一张图片,换到另一个视频中,所以我们可能更需要Roop和FaceFusion,说干就干,开始部署
方案一:Roop
环境配置
首先创建一个conda环境吧,随便叫什么
conda create -n your_env_name python=x.x然后克隆源代码
git clone https://github.com/s0md3v/roop.git
cd roop安装环境,首先要对应cuda、pytorch、onnxruntime、cudnn之间的关系
首先查看自己的cuda版本,可以看到12.8
(base) yanchang@SDFMU3:~/DATA$ nvidia-smi
Tue Sep 30 12:49:19 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 570.133.07 Driver Version: 570.133.07 CUDA Version: 12.8 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Persistence-M | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 2080 Ti Off | 00000000:2F:00.0 Off | N/A |
| 27% 37C P8 22W / 260W | 14MiB / 11264MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
| 1 NVIDIA GeForce RTX 2080 Ti Off | 00000000:86:00.0 Off | N/A |
| 27% 39C P8 15W / 260W | 14MiB / 11264MiB | 0% Default |
| | | N/A |
+-----------------------------------------+------------------------+----------------------+
+-----------------------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=========================================================================================|
| 0 N/A N/A 7276 G /usr/lib/xorg/Xorg 4MiB |
| 0 N/A N/A 1972566 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 7276 G /usr/lib/xorg/Xorg 4MiB |
| 1 N/A N/A 1972566 G /usr/lib/xorg/Xorg 4MiB |
+-----------------------------------------------------------------------------------------+所以去pytorch官网去下载对应的版本https://pytorch.org/get-started/previous-versions/
这里采用v2.7.1
pip install torch==2.7.1 torchvision==0.22.1 torchaudio==2.7.1 --index-url https://download.pytorch.org/whl/cu128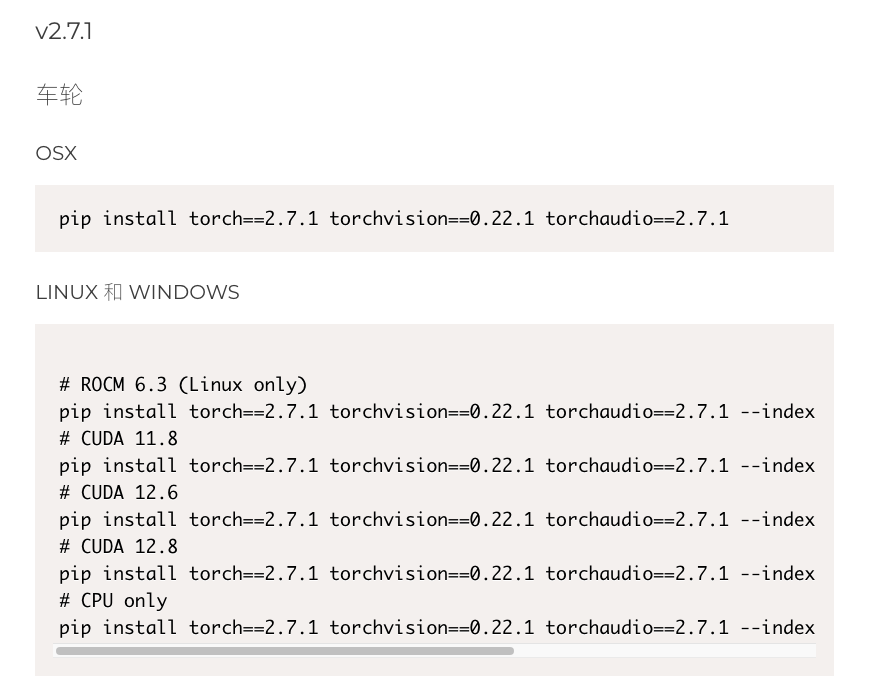
然后去onnxruntime官网去找版本对应https://onnxruntime.ai/docs/execution-providers/CUDA-ExecutionProvider.html#cuda-12x
有很多版本在这里只展示一部分:可以看到我们oNNX支持1.20.X所以手动指定安装版本
pip install onnxruntime-gpu==1.20.1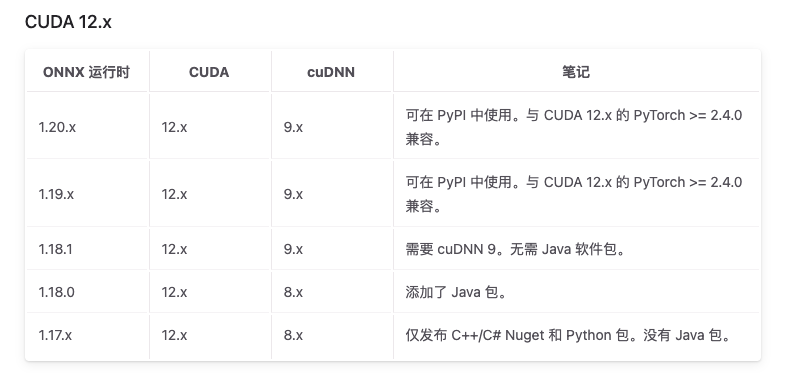
然后安装对应的cuDnn,地址为:https://developer.nvidia.com/cudnn-downloads
选择自己的系统、cpu架构、版本、安装方式然后根据提示

wget https://developer.download.nvidia.com/compute/cuda/repos/ubuntu2404/x86_64/cuda-keyring_1.1-1_all.deb
sudo dpkg -i cuda-keyring_1.1-1_all.deb
sudo apt-get update
sudo apt-get -y install cudnn9-cuda-12到这里基本的环境就配置好了,然后去requirements-headless.txt里删除一些已经安装过的
numpy==1.24.3
opencv-python==4.8.0.74
onnx==1.14.0
insightface==0.7.3
psutil==5.9.5
tk==0.1.0
customtkinter==5.2.0
tkinterdnd2==0.3.0
onnxruntime==1.15.0#删除
tensorflow==2.13.0
opennsfw2==0.10.2
protobuf==4.23.4
tqdm==4.65.0
然后安装
pip install -r requirements-headless.txt启动配置
import subprocess
import os
import re
import time
from tqdm import tqdm # pip install tqdm
import threading
# --- 1. 配置你的文件路径 ---
roop_script_path = os.path.join('roop', 'run.py')
source_face_path = 'source.PNG'
target_video_path = 'target1.mp4'
output_video_path = 'output_result.mp4'
def read_output(stream, process, pbar, status):
"""读取子进程输出并更新进度条"""
frame_patterns = [
r'Processing frame (\d+)/(\d+)',
r'Frame (\d+)/(\d+)',
r'(\d+)/(\d+) frames',
r'Progress:.*?(\d+)/(\d+)'
]
while True:
line = stream.readline()
if not line and process.poll() is not None:
break
if line:
line = line.strip()
print(f"[ROOP] {line}") # 打印所有输出以便调试
# 尝试匹配多种进度格式
for pattern in frame_patterns:
match = re.search(pattern, line, re.IGNORECASE)
if match:
current = int(match.group(1))
total = int(match.group(2))
if total > 0:
pbar.total = total
pbar.n = min(current, total)
pbar.refresh()
status['last_update'] = time.time()
status['current'] = current
status['total'] = total
break
# 检查关键错误信息
if any(error in line.lower() for error in ['error', 'failed', 'traceback', 'exception']):
status['has_error'] = True
print(f"检测到可能的错误: {line}")
# 检查视频合成阶段
if 'creating video' in line.lower() or 'writing video' in line.lower():
status['video_creation'] = True
print("检测到视频合成阶段...")
def run_face_swap():
if not os.path.exists(roop_script_path):
print(f"错误: roop脚本 '{roop_script_path}' 不存在。")
return
if not os.path.exists(source_face_path):
print(f"错误: 源图片 '{source_face_path}' 不存在。")
return
if not os.path.exists(target_video_path):
print(f"错误: 目标视频 '{target_video_path}' 不存在。")
return
command = [
'python', roop_script_path,
'-s', source_face_path,
'-t', target_video_path,
'-o', output_video_path,
'--keep-fps',
'--execution-provider', 'cpu', # 有GPU可用
'--temp-frame-format', 'jpg' # 明确指定临时帧格式
]
print("正在执行换脸操作,请耐心等待...")
print(f"执行的命令: {' '.join(command)}")
try:
# 初始化状态跟踪
status = {
'last_update': time.time(),
'current': 0,
'total': 100,
'has_error': False,
'video_creation': False
}
# 启动进程
process = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1,
universal_newlines=True
)
# 创建进度条
pbar = tqdm(total=100, desc="处理进度", ncols=100)
# 启动线程读取输出
stdout_thread = threading.Thread(
target=read_output,
args=(process.stdout, process, pbar, status)
)
stderr_thread = threading.Thread(
target=read_output,
args=(process.stderr, process, pbar, status)
)
stdout_thread.daemon = True
stderr_thread.daemon = True
stdout_thread.start()
stderr_thread.start()
# 主循环:监控进程状态和超时
timeout = 300 # 5分钟无进度更新则认为卡住
while process.poll() is None:
time.sleep(1)
# 检查是否卡住
if time.time() - status['last_update'] > timeout:
print(f"\n警告: 进程可能已卡住,{timeout}秒无进度更新")
print("尝试强制结束进程...")
process.terminate()
break
# 检查是否进入视频合成阶段但长时间无更新
if status['video_creation'] and time.time() - status['last_update'] > 120:
print("\n视频合成阶段时间较长,请耐心等待...")
status['last_update'] = time.time() # 重置计时器
# 等待进程完全结束
process.wait()
# 关闭进度条
pbar.close()
# 检查结果
if process.returncode == 0:
if os.path.exists(output_video_path):
print(f"\n✅ 处理完成!视频已保存到: {output_video_path}")
print(f"文件大小: {os.path.getsize(output_video_path) / (1024*1024):.2f} MB")
else:
print(f"\n⚠️ 进程正常结束,但输出文件不存在: {output_video_path}")
else:
print(f"\n❌ 处理失败,返回码: {process.returncode}")
if status['has_error']:
print("检测到错误信息,请检查上面的输出")
# 尝试提供解决方案
print("\n可能的解决方案:")
print("1. 检查CUDA是否可用,尝试使用CPU: 将 'cuda' 改为 'cpu'")
print("2. 检查源图片和目标视频的格式和大小")
print("3. 尝试降低视频分辨率或使用更短的视频")
print("4. 检查临时文件夹是否有足够的空间")
except Exception as e:
print(f"执行过程中发生意外错误: {e}")
# 确保进程被终止
try:
process.terminate()
except:
pass
finally:
# 清理临时文件(如果需要)
temp_dir = 'temp'
if os.path.exists(temp_dir):
try:
import shutil
shutil.rmtree(temp_dir)
print(f"已清理临时文件夹: {temp_dir}")
except Exception as e:
print(f"清理临时文件夹失败: {e}")
if __name__ == '__main__':
run_face_swap()
启动环境执行上面的文件即可
效果展示
源图片杰伦

源视频,我的
处理结果
方案二:facefusion
环境配置
环境配置和上面一样配置onnxruntime、cuda、pytorch、cudnn
requirements.txt内容改为
gradio-rangeslider==0.0.8
gradio==5.42.0
numpy
onnx==1.19.0
onnxruntime==1.22.1
opencv-python==4.12.0.88
psutil==7.0.0
tqdm==4.67.1
scipy==1.16.1
启动配置
import subprocess
import os
import re
import time
from tqdm import tqdm
import threading
# --- 配置文件路径 ---
source_face_path = './data/source/source.PNG'
target_video_path = './data/target1.mp4'
output_video_path = './data/output_result.mp4'
def read_output(stream, process, pbar, status):
"""读取子进程输出并更新进度条"""
frame_patterns = [
r'Processing frame (\d+)/(\d+)',
r'Frame (\d+)/(\d+)',
r'(\d+)/(\d+) frames',
r'Progress:.*?(\d+)/(\d+)',
r'(\d+)%', # 百分比进度
r'step (\d+)/(\d+)' # 步骤进度
]
while True:
line = stream.readline()
if not line and process.poll() is not None:
break
if line:
line = line.strip()
print(f"[FaceFusion] {line}")
# 尝试匹配多种进度格式
for pattern in frame_patterns:
match = re.search(pattern, line, re.IGNORECASE)
if match:
# 处理百分比格式
if '%' in line:
percent = int(match.group(1))
pbar.n = percent
pbar.refresh()
status['last_update'] = time.time()
# 处理帧数格式
elif len(match.groups()) >= 2:
current = int(match.group(1))
total = int(match.group(2))
if total > 0:
pbar.total = total
pbar.n = min(current, total)
pbar.refresh()
status['last_update'] = time.time()
status['current'] = current
status['total'] = total
break
# 检查关键错误信息
if any(error in line.lower() for error in ['error', 'failed', 'traceback', 'exception']):
status['has_error'] = True
print(f"❌ 错误: {line}")
# 检查完成信息
if 'completed' in line.lower() or 'finished' in line.lower() or 'success' in line.lower():
status['completed'] = True
print("✅ 检测到处理完成")
def run_facefusion_swap():
"""使用 FaceFusion 进行高质量换脸"""
if not os.path.exists(source_face_path):
print(f"❌ 错误: 源图片 '{source_face_path}' 不存在。")
return
if not os.path.exists(target_video_path):
print(f"❌ 错误: 目标视频 '{target_video_path}' 不存在。")
return
# FaceFusion 高质量命令 - 使用正确的参数格式
command = [
'python', 'facefusion.py',
'headless-run',
'-s', source_face_path,
'-t', target_video_path,
'-o', output_video_path,
'--execution-providers', 'cuda',
'--processors', 'face_swapper', 'face_enhancer', # 关键:使用正确的参数名
'--face-swapper-model', 'inswapper_128_fp16', # 选择一个换脸模型
'--face-enhancer-model', 'gfpgan_1.4', # 人脸增强模型
'--face-enhancer-blend', '80', # 增强混合比例
'--face-detector-model', 'many', # 使用更准确的人脸检测
'--face-detector-score', '0.5', # 人脸检测置信度
'--face-selector-mode', 'reference', # 使用参考人脸模式
'--reference-face-position', '0', # 使用第一个检测到的人脸
'--reference-face-distance', '0.6', # 人脸匹配阈值
'--face-mask-types', 'box', 'occlusion', 'region', # 使用多种掩码类型
'--face-mask-blur', '0.3', # 掩码边缘模糊
'--output-video-encoder', 'libx264', # 视频编码器
'--output-video-quality', '90', # 视频质量
'--temp-frame-format', 'png', # 临时帧格式
'--keep-temp' # 保留临时文件用于调试
]
print("🎯 正在使用 FaceFusion 执行高质量换脸操作...")
print(f"执行的命令: {' '.join(command)}")
try:
# 初始化状态跟踪
status = {
'last_update': time.time(),
'current': 0,
'total': 100,
'has_error': False,
'completed': False
}
# 启动进程
process = subprocess.Popen(
command,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE,
text=True,
bufsize=1,
universal_newlines=True
)
# 创建进度条
pbar = tqdm(total=100, desc="处理进度", ncols=100)
# 启动线程读取输出
stdout_thread = threading.Thread(
target=read_output,
args=(process.stdout, process, pbar, status)
)
stderr_thread = threading.Thread(
target=read_output,
args=(process.stderr, process, pbar, status)
)
stdout_thread.daemon = True
stderr_thread.daemon = True
stdout_thread.start()
stderr_thread.start()
# 主循环:监控进程状态和超时
timeout = 600 # FaceFusion 处理可能需要更长时间
while process.poll() is None:
time.sleep(1)
# 检查是否卡住
if time.time() - status['last_update'] > timeout:
print(f"⚠️ 警告: 进程可能已卡住,{timeout}秒无进度更新")
print("尝试强制结束进程...")
process.terminate()
break
# 等待进程完全结束
process.wait()
# 关闭进度条
pbar.close()
# 检查结果
if process.returncode == 0 or status['completed']:
if os.path.exists(output_video_path):
output_size = os.path.getsize(output_video_path) / (1024*1024)
print(f"\n✅ FaceFusion 处理完成!")
print(f"📁 输出文件: {output_video_path}")
print(f"📊 文件大小: {output_size:.2f} MB")
print("✨ 使用了高质量的人脸增强功能")
else:
print(f"⚠️ 进程正常结束,但输出文件不存在: {output_video_path}")
else:
print(f"❌ 处理失败,返回码: {process.returncode}")
if status['has_error']:
print("检测到错误信息,请检查上面的输出")
except Exception as e:
print(f"❌ 执行过程中发生意外错误: {e}")
# 确保进程被终止
try:
process.terminate()
except:
pass
def run_facefusion_simple():
"""使用 FaceFusion 的简化版本"""
if not os.path.exists(source_face_path):
print(f"❌ 错误: 源图片 '{source_face_path}' 不存在。")
return
if not os.path.exists(target_video_path):
print(f"❌ 错误: 目标视频 '{target_video_path}' 不存在。")
return
# 简化命令 - 只使用基本参数
command = [
'python', 'facefusion.py',
'headless-run',
'-s', source_face_path,
'-t', target_video_path,
'-o', output_video_path,
'--execution-providers', 'cpu',
'--processors', 'face_swapper', 'face_enhancer',
'--face-enhancer-model', 'gfpgan_1.4'
]
print("🔄 正在使用 FaceFusion 简化版执行换脸操作...")
print(f"执行的命令: {' '.join(command)}")
try:
# 直接运行并显示输出
result = subprocess.run(command, capture_output=True, text=True)
# 打印所有输出
print("📋 标准输出:")
print(result.stdout)
if result.stderr:
print("⚠️ 标准错误:")
print(result.stderr)
if result.returncode == 0:
if os.path.exists(output_video_path):
output_size = os.path.getsize(output_video_path) / (1024*1024)
print(f"\n✅ FaceFusion 处理完成!")
print(f"📁 输出文件: {output_video_path}")
print(f"📊 文件大小: {output_size:.2f} MB")
else:
print(f"⚠️ 进程正常结束,但输出文件不存在: {output_video_path}")
else:
print(f"❌ 处理失败,返回码: {result.returncode}")
except Exception as e:
print(f"❌ 执行过程中发生意外错误: {e}")
def run_facefusion_minimal():
"""使用 FaceFusion 的最简版本"""
if not os.path.exists(source_face_path):
print(f"❌ 错误: 源图片 '{source_face_path}' 不存在。")
return
if not os.path.exists(target_video_path):
print(f"❌ 错误: 目标视频 '{target_video_path}' 不存在。")
return
# 最简命令 - 只使用必需参数
command = [
'python', 'facefusion.py',
'headless-run',
'-s', source_face_path,
'-t', target_video_path,
'-o', output_video_path,
'--execution-providers', 'GPU'
]
print("🔧 正在使用 FaceFusion 最简版执行换脸操作...")
print(f"执行的命令: {' '.join(command)}")
try:
# 直接运行并显示输出
result = subprocess.run(command, capture_output=True, text=True)
# 打印所有输出
print("📋 标准输出:")
print(result.stdout)
if result.stderr:
print("⚠️ 标准错误:")
print(result.stderr)
if result.returncode == 0:
if os.path.exists(output_video_path):
output_size = os.path.getsize(output_video_path) / (1024*1024)
print(f"\n✅ FaceFusion 处理完成!")
print(f"📁 输出文件: {output_video_path}")
print(f"📊 文件大小: {output_size:.2f} MB")
else:
print(f"⚠️ 进程正常结束,但输出文件不存在: {output_video_path}")
else:
print(f"❌ 处理失败,返回码: {result.returncode}")
except Exception as e:
print(f"❌ 执行过程中发生意外错误: {e}")
def check_facefusion_installation():
"""检查 FaceFusion 是否正确安装"""
try:
result = subprocess.run(
['python', 'facefusion.py', '--version'],
capture_output=True, text=True
)
if result.returncode == 0:
print(f"✅ FaceFusion 版本: {result.stdout.strip()}")
return True
else:
print("❌ FaceFusion 未正确安装")
return False
except Exception as e:
print(f"❌ 检查 FaceFusion 安装时出错: {e}")
return False
if __name__ == '__main__':
print("=" * 50)
print("FaceFusion 换脸脚本")
print("=" * 50)
# 检查安装
if not check_facefusion_installation():
print("请先安装 FaceFusion: git clone https://github.com/facefusion/facefusion.git")
exit(1)
# 首先尝试完整版本
print("\n🚀 尝试使用完整版 FaceFusion...")
run_facefusion_swap()
# 如果完整版本失败,尝试简化版本
if not os.path.exists(output_video_path):
print("\n🔄 完整版失败,尝试简化版本...")
run_facefusion_simple()
# 如果简化版本失败,尝试最简版本
if not os.path.exists(output_video_path):
print("\n🔧 简化版失败,尝试最简版本...")
run_facefusion_minimal()
# 最终检查
if os.path.exists(output_video_path):
print(f"\n🎉 换脸操作成功完成!")
print(f"📺 可以在以下位置查看结果: {output_video_path}")
else:
print(f"\n💥 所有换脸操作都失败了,请检查错误信息")效果展示
总结
毫无疑问,Roop更模糊一些,而facefusion质量更好一些
经过实际测试对比:
ROOP:
优点:部署简单,处理速度快
缺点:换脸效果相对模糊,细节处理不够精细
适用场景:快速简单的换脸需求,对画质要求不高
FaceFusion:
优点:换脸质量高,细节处理优秀,支持多人脸和增强功能
缺点:部署相对复杂,处理时间较长
适用场景:高质量换脸需求,对画质有较高要求
推荐选择: 如果追求高质量的换脸效果,FaceFusion是更好的选择;如果只需要快速简单的换脸,ROOP可以满足基本需求。
注意事项
硬件要求: 需要较强的GPU支持,建议至少8GB显存
软件兼容性: 注意CUDA、PyTorch、ONNX Runtime版本之间的兼容性
法律合规: 请确保在合法合规的范围内使用这些技术
隐私保护: 尊重他人隐私,不要未经许可使用他人肖像
通过自己部署这些开源项目,你可以完全掌控换脸过程,享受无限制的创作自由!